Качество обслуживания в сетях IP-телефонии
Глава 10 Качество обслуживания в сетях IP-телефонии
10.1 Что понимается под QoS?
Характер информации, передаваемой по сетям с маршрутизацией пакетов IP, сегодня драматически меняется. Кроме передачи данных, IP-сети используются для прослушивания музыкальных программ, просмотра видеоклипов, обмена речевой информацией, проведения мультимедийных конференций, оперативного контроля/управления, сетевых игр и других приложений реального времени.
Протокол IP, подробно рассмотренный в Главе 4, первоначально не предназначался для обмена информацией в реальном времени. Ведь пакеты одного и того же потока данных маршрутизируются по сети независимо друг от друга, а время обработки пакетов в узлах может меняться в широких пределах, в силу чего такие параметры передачи как задержка и вариация задержки пакетов также могут меняться. А параметры качества сетевых услуг, обеспечивающих передачу информации в реальном времени, как известно, сильно зависят от характеристик задержек пакетов, в которых эта информация переносится.
Транспортные протоколы стека TCP/IP, реализуемые в оборудовании пользователей и функционирующие поверх протокола IP, также не обеспечивают высокого качества обслуживания трафика, чувствительного к задержкам. Протокол TCP, хоть и гарантирует достоверную доставку информации, но переносит ее с непредсказуемыми задержками. Протокол UDP, который, как правило, используется для переноса информации в реальном времени, обеспечивает меньшее, по сравнению с протоколом TCP, время задержки, но, как и протокол IP, не содержит никаких механизмов обеспечения качества обслуживания.
Кроме того, в самой сети Интернет нет никаких механизмов, поддерживающих на должном уровне качество передачи информации в реальном времени. Иными словами, ни в узлах IP-сетей, ни в оборудовании пользователей в настоящее время нет средств, обеспечивающих гарантированное качество обслуживания.
Вместе с тем, налицо необходимость получения от сети гарантий, что в периоды перегрузки пакеты с информацией, чувствительной к задержкам, не будут простаивать в очередях или, по крайней мере, получат более высокий приоритет, чем пакеты с информацией, не чувствительной к задержкам.
Иначе говоря, необходимо гарантировать доставку такой информации, как речь, видео и мультимедиа, в реальном времени с минимально возможной задержкой. Для этой цели в сети должны быть реализованы механизмы, гарантирующие нужное качество обслуживания (Quality of Service - QoS). Анализу таких механизмов и посвящена эта глава.
Идеальной была бы следующая ситуация. Приложение “договаривается” с сетью о том, что пакеты такого-то потока данных со средней скоростью передачи Х Кбит/с будут доставляться от одного конца соединения к другому с задержкой не более Y мс, и что сеть в течение всего соединения будет следить за выполнением этого договора. Кроме указанной характеристики, сеть должна поддерживать согласованные значения таких параметров передачи как минимально доступная полоса частот, максимальное изменение задержки (джиттер), максимальные потери пакетов.
В конечном счете, качество обслуживания зависит не только от сети, но и от оборудования пользователя. Слабые системные ресурсы оборудования пользователя - малый объем оперативной памяти, невысокая производительность центрального процессора и др. -могут сделать показатели качества обслуживания неприемлемыми для пользователя вне зависимости от того, как соблюдает “договоренность” сеть. Хорошее качество обслуживания достигается лишь тогда, когда пользователь удовлетворительно оценивает работу системы в целом.
Следует отметить, что высокое качество обслуживания представляет интерес не только для конечного пользователя, но и для самого поставщика услуг. Например, исследования, проведенные в сетях мобильной связи, показали, что с улучшением качества передачи речи абоненты чаще и дольше пользуются услугами таких сетей, что означает увеличение годовых доходов операторов.
Чтобы добиться гарантий качества обслуживания от сетей, изначально на это не ориентированных, необходимо “наложить” на сеть так называемую QoS-архитектуру, которая включает в себя поддержку качества на всех уровнях стека протоколов TCP/IP и во всех сетевых элементах.
Но и при этом обеспечение гарантированного качества обслуживания все равно остается самым слабым местом процесса передачи информации от источника к приемнику.
Поскольку все больше приложений становятся распределенными, все больше возрастает потребность в поддержке качества обслуживания на нижних сетевых уровнях. Это может вызвать определенные трудности, так как даже стандартные операционные системы рабочих станций не поддерживают доставку информации в реальном времени.
Кроме того, качество обслуживания - это относительное понятие;
его смысл зависит от приложения, с которым работает пользователь. Как уже отмечалось раньше, разные приложения требуют разных уровней или типов качества. Например, скорее всего, пользователя не огорчит тот факт, что его текстовый файл будет передаваться на секунду дольше, или что за первую половину времени передачи будет передано 80% файла, а за вторую - 20%. В то же время, при передаче речевой информации такого рода явления весьма нежелательны или даже недопустимы.
10.2 Качество обслуживания в сетях пакетной коммутации
Идея обеспечить гарантированное качество обслуживания в сетях передачи данных впервые возникла в 1970 году, когда некий пользователь получил вместо одних данных другие. Идея была воплощена в сети Х.25. Однако пакетные системы Х.25, производя проверку ошибок на каждом сетевом узле, вносили задержку порядка нескольких сотен миллисекунд в каждом узле на пути информации от отправителя до получателя.
В сетевых узлах (коммутаторах пакетов) высокоскоростных транспортных сетей Frame Relay проверка и коррекция ошибок не производятся. Эти функции возложены на оборудование пользователя, вследствие чего задержка при передаче информации по таким сетям намного ниже, чем в сетях X. 25.
Одной из широко известных технологий пакетной передачи с гарантированным качеством обслуживания является транспортная технология ATM. И хотя не так давно на ATM возлагались огромные надежды (предполагалось, например, использование ATM в качестве базы для широкополосных сетей ISDN), эта технология не получила широкого распространения из-за своей сложности и высокой стоимости оборудования.
Скорее всего, технология ATM будет использоваться на магистральных участках сетей связи до тех пор, пока ее не вытеснят более простые и скоростные транспортные технологии.
Но самой популярной сегодня технологией пакетной передачи информации является технология маршрутизации пакетов IP. Объем потоков данных, передаваемых по глобальной информационной сети Интернет, удваивается каждые три месяца. Частично это происходит из-за постоянного увеличения количества новых пользователей сети Интернет, а также из-за того, что мультимедийная передача и видеоконференции через Интернет стали, наконец-то, доступны и популярны среди обеспеченных пользователей. Качество обслуживания в этой сети привлекает все более пристальное внимание специалистов и пользователей, так как в Интернет заключается все больше сделок и контрактов, а рост ее пропускной способности несколько отстает от роста спроса.
10.3 Трафик реального времени в IP-сетях
Все большую часть трафика в IP-сетях составляют потоки информации, чувствительной к задержкам. Максимальная задержка не должна превышать нескольких десятых долей секунды, причем сюда входит и время обработки информации на конечной станции. Вариацию задержки также необходимо свести к минимуму. Кроме того, необходимо учитывать, что при сжатии информации, обмен которой должен происходить в реальном времени, она становится более чувствительной к ошибкам, возникающим при передаче, и их нельзя исправлять путем переспроса именно из-за необходимости передачи в реальном времени.
Телефонный разговор - это интерактивный процесс, не допускающий больших задержек. В соответствии с рекомендацией ITU-T G. 114 для большинства абонентов задержка речевого сигнала на 150 мс приемлема, а на 400 мс - недопустима.
Общая задержка речевой информации делится на две основные части - задержка при кодировании и декодировании речи в шлюзах или терминальном оборудовании пользователей (об этом рассказывалось в главе 3) и задержка, вносимая самой сетью. Уменьшить общую задержку можно двумя путями: во-первых, спроектировать инфраструктуру сети таким образом, чтобы задержка в ней была минимальной, и, во-вторых, уменьшить время обработки речевой информации шлюзом.
Для уменьшения задержки в сети нужно сокращать количество транзитных маршрутизаторов и соединять их между собой высокоскоростными каналами. А для сглаживания вариации задержки можно использовать такие эффективные методы как, например, механизмы резервирования сетевых ресурсов.
IP-телефонию часто считают частью пакета услуг Интернет-провайдеров, что, вообще говоря, неверно. Известно множество примеров, когда технология передачи речевой информации внедрялась в корпоративные IP-сети и когда строились (в том числе, в России) выделенные сети IP-телефонии.
Как правило, с корпоративными сетями все обстоит сравнительно просто. Они имеют ограниченные размеры и контролируемую топологию, а характер трафика обычно бывает известен заранее. Возьмем простой пример: речь передается по существующей ЛВС, которая слишком загружена, чтобы обеспечить приемлемое качество обслуживания. Решением этой проблемы будет изоляция серверов и клиентов, работающих с графиком данного типа, и сегментация сети. Разбить сеть на сегменты можно, либо установив коммутатор Ethernet, либо добавив порты в маршрутизатор.
Выделенные сети IP-телефонии обычно используются для междугородной и международной связи. Такие сети лучше строить по иерархическому принципу, возлагая на каждый уровень иерархии свои функции. На входе в сеть главное - обеспечить подключение речевых шлюзов, а внутри сети - высокоскоростную пересылку пакетов. В такой сети очень просто производить расширение и внедрять новые услуги. Проблема проектирования также не доставляет особых проблем: характер трафика определен, полоса пропускания также легко рассчитывается. Трафик однотипный, а значит, не требуется вводить приоритетность пакетов.
В сетях традиционных операторов обслуживается трафик разных видов, поэтому в таких сетях, чтобы обеспечить приемлемое качество, целесообразно применять дифференцированное обслуживание разнотипного трафика (Diff-Serv).
10.4 Дифференцированное обслуживание разнотипного трафика - Diff-Serv
Для обеспечения гарантированного качества обслуживания комитет IETF разработал модель дифференцированного обслуживания разнотипного трафика - Diff-Serv.
В соответствии с этой моделью байт ToS (Type of Service) в заголовке IP-пакета получил другое название DS (Differentiated Services), а шесть его битов отведены под код Diff-Serv. Каждому значению этого кода соответствует свой класс PHB (Per-Hop Behavior Forwarding Class), определяющий уровень обслуживания в каждом из сетевых узлов. Пакеты каждого класса должны обрабатываться в соответствии с определенными для этого класса требованиями к качеству обслуживания.
Модель Diff-Serv описывает архитектуру сети как совокупность пограничных участков и ядра. Пример сети согласно модели Diff-Serv приведен на рисунке 10.1.
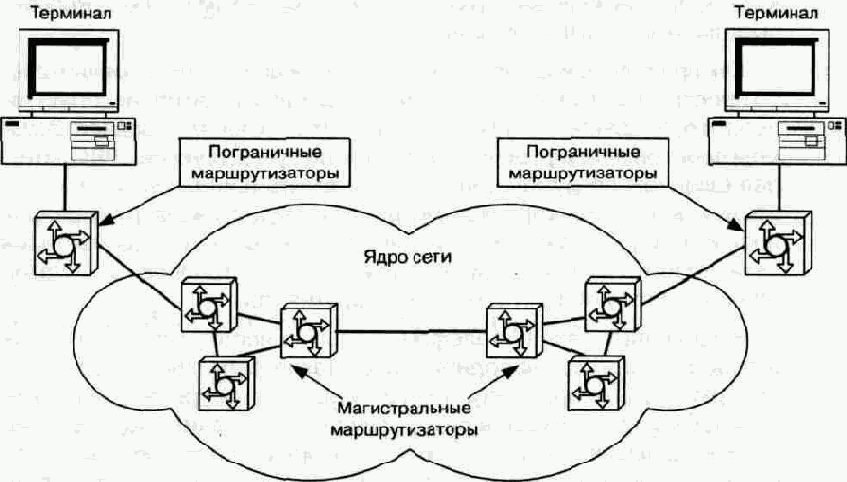
Поступающий в сеть трафик классифицируется и нормализуется пограничными маршрутизаторами. Нормализация трафика предусматривает измерение его параметров, проверку соответствия заданным правилам предоставления услуг, профилирование (при этом пакеты, не укладывающиеся в рамки установленных правил, могут быть отсеяны) и другие операции. В ядре магистральные маршрутизаторы обрабатывают трафик в соответствии с классом PHB, код которого указан в поле DS.
Достоинства модели Diff-Serv состоят в том, что она, во-первых, обеспечивает единое понимание того, как должен обрабатываться трафик определенного класса, а во-вторых, позволяет разделить весь трафик на относительно небольшое число классов и не анализировать каждый информационный поток отдельно. К настоящему времени для Diff-Serv определено два класса трафика:
• класс срочной пересылки пакетов (Expedited Forwarding PHB Group);
• класс гарантированной пересылки пакетов (Assured Forwarding PHB Group).
Механизм обеспечения QoS на уровне сетевого устройства, применяемый в Diff-Serv, включает в себя четыре операции. Сначала пакеты классифицируются на основании их заголовков. Затем они маркируются в соответствии с произведенной классификацией (в поле Diff-Serv). В зависимости от маркировки выбирается алгоритм передачи (при необходимости - с выборочным удалением пакетов), позволяющий избежать заторов в сети.
Заключительная операция, чаще всего, состоит в организации очередей с учетом приоритетов[15].
Хотя эта модель и не гарантирует качество обслуживания на 100%, у нее есть серьезные преимущества. Например, нет необходимости в организации предварительного соединения и в резервировании ресурсов. Атак как в модели Diff-Serv используется небольшое, фиксированное количество классов и трафик абонентов распределяется по общим очередям, не требуется высокая производительность сетевого оборудования.
10.5 Интегрированное обслуживание IntServ
Этот подход явился одной из первых попыток комитета IETF разработать действенный механизм обеспечения качества обслуживания в IP-сетях. Для трафика реального времени вводятся два класса обслуживания: контролируемой загрузки сети и гарантированного обслуживания.
Классу гарантированного обслуживания предоставляется определенная полоса пропускания, а также гарантируются задержка в определенных пределах и отсутствие потерь при переполнении очередей.
Класс контролируемой загрузки сети идентичен традиционному подходу “best effort”, но уровень QoS для уже обслуживаемого потока данных остается неизменным при увеличении нагрузки в сети.
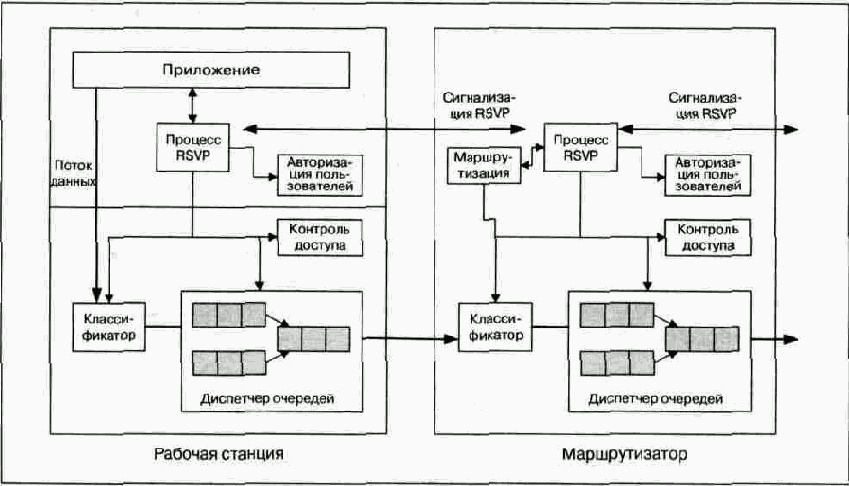
Основными компонентами модели IntServ являются система резервирования ресурсов, система контроля доступа, классификатор и диспетчер очередей. Архитектура модели изображена на рис. 10.2.
Спецификация потока (flow specification) нужна для определения необходимого уровня качества обслуживания потока.
Система контроля доступа, получив запрос сеанса связи, в зависимости от наличия требуемых ресурсов, либо допускает этот запрос к дальнейшей обработке, либо дает отказ. Классификатор определяет класс обслуживания на основе содержания поля приоритета в заголовке. Диспетчер определяет способ организации и механизм обслуживания очереди. Система резервирования ресурсов использует специальный протокол сигнализации, который служит для запроса приложением нужного ему уровня качества обслуживания и для координации обработки этого запроса всеми устройствами сети.
Этому протоколу посвящен следующий параграф.
10.6 Протокол резервирования ресурсов - RSVP
10.6.1 Общие принципы протокола
Чтобы обеспечить должное качество обслуживания трафика речевых и видеоприложений, необходим механизм, позволяющий приложениям информировать сеть о своих требованиях. На основе этой информации сеть может резервировать ресурсы для того, чтобы гарантировать выполнение требований к качеству, или отказать приложению, вынуждая его либо пересмотреть требования, либо отложить сеанс связи. В роли такого механизма выступает протокол резервирования ресурсов RSVP (Resource Reservation Protocol).
При одноадресной передаче процесс резервирования выглядит довольно просто. Многоадресная же рассылка делает задачу резервирования ресурсов гораздо более сложной. Приложения, использующие многоадресную рассылку, могут генерировать огромные объемы трафика, например, в случае организации видеоконференции с большой рассредоточенной группой участников. Однако в этом случае существуют возможности значительного снижения трафика.
Во-первых, некоторым участникам конференции в какие-то периоды времени может оказаться ненужной доставка к ним всех данных от всех источников - например, участник может быть заинтересован в получении речевой информации и не заинтересован в получении видеоинформации.
Во-вторых, оконечное оборудование некоторых участников конференции может оказаться способным обрабатывать только часть передаваемой информации. Например, поток видеоданных может состоять из двух компонентов - базового и дополнительного, нужного для получения более высокого качества изображения. Оборудование части пользователей может не иметь достаточной вычислительной мощности для обработки компонентов, обеспечивающих высокое разрешение, или может быть подключено к сети через канал, не обладающий необходимой пропускной способностью.
Процедура резервирования ресурсов позволяет приложениям заранее определить, есть ли в сети возможность доставить многоадресный трафик всем адресатам в полном объеме, и, если нужно, принять решение о доставке отдельным получателям усеченных версий потоков.
RSVP - это протокол сигнализации, который обеспечивает резервирование ресурсов для предоставления в IP-сетях услуг эмуляции выделенных каналов. Протокол позволяет системам запрашивать, например: гарантированную пропускную способность такого канала, предсказуемую задержку, максимальный уровень потерь. Но резервирование выполняется лишь в том случае, если имеются требуемые ресурсы.
В основе протокола RSVP лежат три компонента:
• сеанс связи, который идентифицируется адресом получателя данных;
• спецификация потока, которая определяет требуемое качество обслуживания и используется узлом сети, чтобы установить соответствующий режим работы диспетчера очередей;
• спецификация фильтра, определяющая тип графика, для обслуживания которого запрашивается ресурс.
10.6.2 Процедура резервирования ресурсов
Отправитель данных передает на индивидуальный или групповой адрес получателя сообщение Path, в котором указывает желательные характеристики качества обслуживания трафика - верхнюю и нижнюю границу полосы пропускания, величину задержки и вариации задержки. Сообщение Path пересылается маршрутизаторами сети по направлению к получателю данных с использованием таблиц маршрутизации в узлах сети. Каждый маршрутизатор, поддерживающий протокол RSVP, получив сообщение Path, фиксирует определенный элемент “структуры пути” - адрес предыдущего маршрутизатора. Таким образом, в сети образуется фиксированный маршрут. Поскольку сообщения Path содержат те же адреса отправителя и получателя, что и данные, пакеты будут маршрутизироваться корректно даже через сетевые области, не поддерживающие протокол RSVP.
Сообщение Path должно нести в себе шаблон данных отправителя (Sender Template), описывающий тип этих данных. Шаблон специфицирует фильтр, который отделяет пакеты данного отправителя от других пакетов в пределах сессии (по IP-адресу отправителя и, возможно, по номеру порта). Кроме того, сообщение Path должно содержать спецификацию потока данных отправителя Tspec, которая определяет характеристики этого потока.
Спецификация Tspec используется, чтобы предотвратить избыточное резервирование.
Шаблон данных отправителя имеет тот же формат, что и спецификация фильтра в сообщениях Resv (см. ниже).
Приняв сообщение Path, его получатель передает к маршрутизатору, от которого пришло это сообщение (т.е. по направлению к отправителю), запрос резервирования ресурсов - сообщение Resv. В дополнение к информации Tspec, сообщение Resv содержит спецификацию запроса (Rspec}, в которой указываются нужные получателю параметры качества обслуживания, и спецификацию фильтра (filter-spec), определяющую, к каким пакетам сессии относится данная процедура (по IP-адресу отправителя и, возможно, по номеру порта).
Когда получатель данных передает запрос резервирования, он может запросить передачу ему ответного сообщения, подтверждающего резервирование.
При получении сообщения Resv каждый маршрутизатор резервируемого пути, поддерживающий протокол RSVP, определяет, приемлем ли этот запрос, для чего выполняются две процедуры. С помощью механизмов управления доступом проверяется, имеются ли у маршрутизатора ресурсы, необходимые для поддержки запрашиваемого качества обслуживания, а с помощью процедуры авторизации пользователей (policy control) - правомерен ли запрос резервирования ресурсов. Если запрос не может быть удовлетворен, маршрутизатор отвечает на него сообщением об ошибке.
Если же запрос приемлем, данные о требуемом качестве обслуживания поступают для обработки в соответствующие функциональные блоки (способ обработки параметров QoS маршрутизатором в протоколе RSVP не определен), и маршрутизатор передает сообщение Resv следующему (находящемуся ближе к отправителю данных) маршрутизатору. Это сообщение несет в себе спецификацию flow/spec, содержащую два набора параметров:
• “Rspec”, который определяет желательное QoS,
• “Tspec”, который описывает информационный поток.
Вместе flowspec и filterspec представляют собой дескриптор потока, используемый маршрутизатором для идентификации каждой процедуры резервирования ресурсов.
Когда маршрутизатор, ближайший к инициатору процедуры резервирования, получает сообщение Resv и выясняет, что запрос приемлем, он передает подтверждающее сообщение получателю данных. При групповом резервировании учитывается тот факт, что в точках слияния дерева доставки несколько потоков, для которых производится резервирование, сливаются в один, так что подтверждающее сообщение передает маршрутизатор, находящийся в точке их слияния.
После окончания вышеописанной процедуры ее инициатор начинает передавать данные и на их пути к получателю будет обеспечено заданное QoS.
Для простой выделенной линии требуемое QoS будет получено с помощью диспетчера пакетов в драйвере уровня звена данных. Если технология уровня звена данных предусматривает свои средства управления QoS, протокол RSVP должен согласовать получение нужного QoS с этим уровнем.
Отменить резервирование можно двумя путями - прямо или косвенно. В первом случае отмена производится по инициативе отправителя или получателя с помощью специальных сообщений RSVP. Во втором случае резервирование отменяется по таймеру, ограничивающему срок существования резервирования.
Протокол RSVP поддерживает улучшенную версию однопроходного варианта алгоритма, известного под названием OPWA (One Path With Advertising) (OPWA95). С помощью OPWA управляющие пакеты RSVP, передаваемые вдоль маршрута, могут быть использованы для переноса данных, которые позволяют предсказывать QoS маршрута в целом.
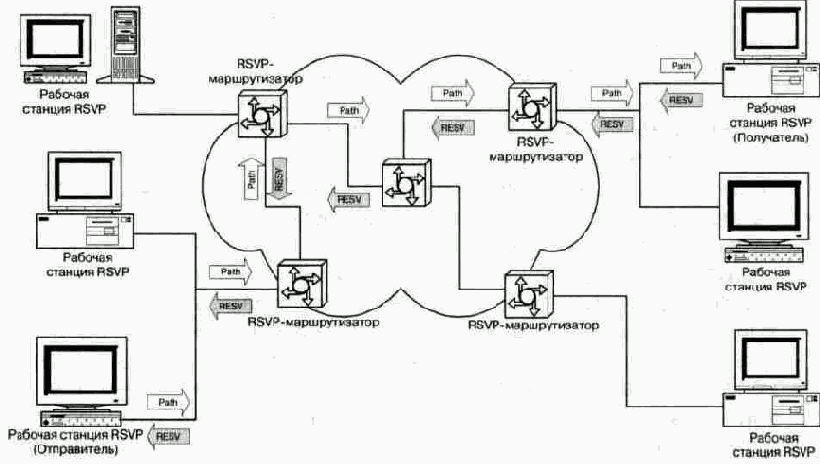
Рис. 10.3 Резервирование ресурсов при помощи протокола RSVP
Сточки зрения узла сети работа протокола RSVP выглядит так:
1. Получатель вступает в группу многоадресной рассылки, отправляя соответствующее сообщение протокола IGMP ближайшему маршрутизатору;
2. Отправитель передает сообщение по адресу группы;
3. Получатель принимает сообщение Path, идентифицирующее отправителя;
4. Теперь получатель имеет информацию об обратном пути и может отправлять сообщение Resv с дескрипторами потока;
5. Сообщения Resv передаются по сети отправителю;
6. Отправитель начинает передачу данных;
7. Получатель начинает передачу данных.
Несмотря на то, что протокол RSVP является важным инструментом в арсенале средств, обеспечивающих гарантированное качество обслуживания, этот протокол не может решить все проблемы, связанные с QoS. Основные недостатки протокола RSVP - большой объем служебной информации и большие затраты времени на организацию резервирования.
Протокол RSVP не размещается в крупномасштабных средах. В лучшем случае, магистральный маршрутизатор имеет возможность резервировать ресурсы для нескольких тысяч потоков и управлять очередями для каждого из них.
Протокол RSVP работает с пакетами IP и не затрагивает схем сжатия, циклического контроля (CRCs) или работы с кадрами уровня звена данных (Frame Relay, PPP, HDLC).
Например, при использовании для IP-телефонии алгоритма кодирования речи G.729, обеспечивающего, с учетом сжатия заголовков RTP-пакетов, передачу речи со скоростью около 11 Кбит/с, в оборудовании Cisco по протоколу RSVP резервируется ресурс с пропускной способностью 24 Кбит/с. Другими словами, в канале с пропускной способностью 56 Кбит/с разрешено резервировать ресурс только для двух потоков со скоростью 24 Кбит/с каждый, даже если полоса пропускания располагает ресурсом для трех потоков со скоростью 11 Кбит/с каждый. Чтобы обойти это ограничение, можно применить следующий прием. Средствами эксплуатационного управления функциональному блоку RSVP маршрутизатора сообщается, например, что канал с фактической полосой пропускания 56 Кбит/с имеет, якобы, пропускную способность 100 Кбит/с и что допускается использовать для резервирования 75% его полосы пропускания. Такой “обман” разрешит протоколу RSVP резервировать полосу пропускания, которая необходима для трех речевых потоков, закодированных по алгоритму G.729. Очевидно, что при этом есть опасность перегрузки канала с реальной полосой 56 Кбит/с, если сжатие заголовков RTP-пакетов не применяется.
10.7 Технология MPLS
Технология многопротокольной коммутации по меткам (Multiprotocol Label Switching - MPLS), разработанная комитетом IETF, явилась результатам слияния нескольких разных механизмов, таких как IP Switching (Ipsilon), Tag Switching (Cisco Systems), Aris (IBM) и Cell Switch Router (Toshiba).
В архитектуре MPLS собраны наиболее удачные элементы всех упомянутых механизмов, и благодаря усилиям-IETF и компаний, заинтересованных в скорейшем продвижении этой технологии на рынке, она превратилась в стандарт Internet.
В обычных IP-сетях любой маршрутизатор, находящийся на пути следования пакетов, анализирует заголовок каждого пакета, чтобы определить, к какому потоку этот пакет относится, и выбрать направление для его пересылки к следующему маршрутизатору. При использовании технологии MPLS соответствие между пакетом и потоком устанавливается один раз, на входе в сеть MPLS. Более точно, соответствие устанавливается между пакетом и так называемым “классом эквивалентности пересылки” FEC (Forwarding Equivalence Class);
к одному FEC относятся пакеты всех потоков, пути следования которых через сеть (или часть сети) совпадают. С точки зрения выбора ближайшего маршрутизатора, к которому их надо пересылать, все пакеты одного FEC неразличимы. Пакеты снабжаются метками -идентификаторами небольшой и фиксированной длины, которые определяют принадлежность каждого пакета тому или иному классу FEC. Метка имеет локальное значение - она действительна на участке между двумя соседними маршрутизаторами, являясь исходящей меткой определенного FEC для одного из них и входящей - для второго. Второй маршрутизатор, пересылая пакет этого FEC к следующему маршрутизатору, снабжает его другой меткой, которая идентифицирует тот же FEC на следующем участке маршрута, и т.д. Таким образом, каждый FEC имеет свою систему меток.
Использование меток значительно упрощает процедуру пересылки пакетов, так как маршрутизаторы обрабатывают не весь заголовок IP-пакета, а только метку, что занимает значительно меньше времени.
На рис. 10.4 показана, в качестве примера, простейшая MPLS-сеть, содержащая маршрутизаторы двух типов:
• пограничные маршрутизаторы MPLS (Label Edge Routers - LER),
• транзитные маршрутизаторы MPLS (Label Switching Routers - LSR).
По отношению к любому потоку пакетов, проходящему через -- MPLS-сеть, один LER является входным, а другой LER - выходным.
Входной LER анализирует заголовок пришедшего извне пакета, устанавливает, какому FEC он принадлежит, снабжает этот пакет меткой, которая присвоена данному FEC, и пересылает пакет к соответствующему LSR. Далее, пройдя, в общем случае, через несколько LSR, пакет попадает к выходному LER, который удаляет из пакета метку, анализирует заголовок пакета и направляет его к адресату, находящемуся вне MPLS-сети.
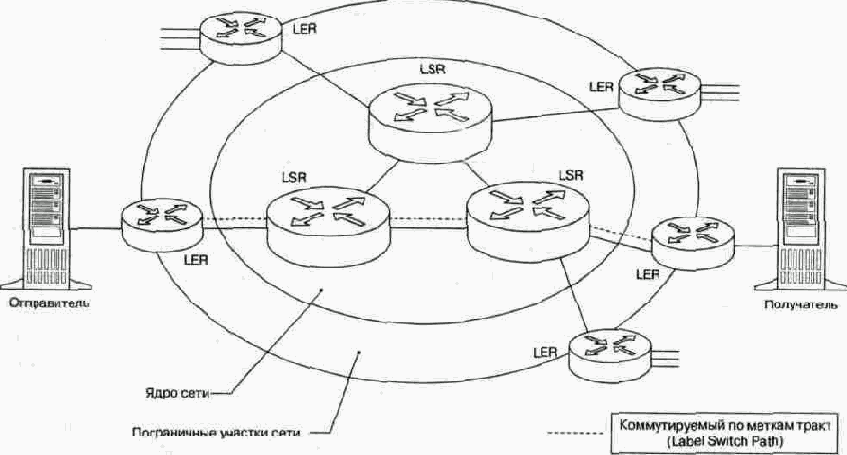
Последовательность (LER^, LSR,,..., LSR„, LER^) маршрутизаторов, через которые проходят пакеты, принадлежащие одному FEC, образует виртуальный коммутируемый по меткам тракт LSP (Label Switched Path). Так как один и тот же LER для одних потоков является входным, а для других-выходным, в сети, содержащей N LER, в простейшем случае может существовать N(N-1) FEC и, соответственно, N(N-1)LSP.
Заметим, однако, что потоки пакетов из разных FEC, приходящие к одному выходному LER от разных входных LER, могут в каких-то LSR сливаться в более мощные потоки, каждый из которых образует новый FEC со своей системой меток. Возможно и обратное, то есть группа потоков может идти до некоторого LSR по общему маршруту и, следовательно, принадлежать одному и тому же FEC, а затем разветвиться, и тогда каждая ветвь будет иметь свой FEC (со своей системой меток). Кроме того, существует возможность образования внутри некоторого LSP одного или нескольких вложенных в него LSP (так называемых LSP-туннелей).
То обстоятельство, что система меток, присваиваемых пакету, может изменяться, приводит к образованию так называемого “стека меток”. При переходе потока пакетов в другой FEC, метка нового FEC помещается поверх метки прежнего FEC и используется для коммутации, а прежняя метка сохраняется под ней, но не используется до тех пор, пока не восстановится прежний FEC. Ясно, что если FEC пакета меняется несколько раз, в стеке накапливается несколько меток.
Все это, с одной стороны, демонстрирует, насколько широки возможности MPLS в части распределения ресурсов сети при ее проектировании и в части их оперативного перераспределения при эксплуатации, но, с другой стороны, предъявляет непростые требования к средствам, с помощью которых устанавливается соответствие “FEC-метка” в каждом LER и LSR сети.
Итак, метка, помещаемая в некоторый пакет, представляет FEC, к которому этот пакет относится. Как правило, отнесение пакета к определенному классу производится на основе сетевого адреса получателя. Метка может быть помещена в пакет разными способами -вписываться в специальный заголовок, “вставляемый” либо между заголовками уровня звена данных и сетевого уровня, либо в свободное и доступное поле заголовка какого-то одного из этих двух уровней, если таковое имеется. В любом случае этот специальный заголовок содержит поле, куда записывается значение метки, и несколько служебных полей, среди которых имеется и то, которое представляет особый интерес с точки зрения данной главы - поле QoS (три бита, т.е. до восьми классов качества обслуживания).
Метки для каждого FEC всегда назначаются “снизу”, то есть либо выходным LER, либо тем LSR, который является для этого FEC “нижним” (расположенным ближе к адресату), и распределяются им по тем маршрутизаторам, которые расположены “выше” (ближе к отправителю).
Распределение меток может быть независимым или упорядоченным. В первом случае LSR может уведомить вышестоящий LSR о привязке метки к FEC еще до того, как получит информацию о привязке “метка-FEC” от нижестоящего маршрутизатора. Во втором случае высылать подобное уведомление разрешается только после получения таких сведений “снизу”. Метки могут выдаваться нижним маршрутизатором как по собственной инициативе, так и по запросу верхнего. Наконец, возможен “либеральный” или “консервативный” режим распределения меток. В либеральном режиме нижний LSR раздает метки вышестоящим LSR, как имеющим с ним прямую связь, так и доступным лишь через промежуточные LSR. В консервативном режиме вышестоящий LSR обязан принять метку, если ее выдает смежный LSR, но может отказаться от метки, пришедшей к нему транзитом.
Как уже отмечалось, метка должна быть уникальной лишь для каждой пары смежных LSR. Поэтому одна и та же метка в любом LSR может быть связана с несколькими FEC, если разным FEC принадлежат пакеты, идущие от разных маршрутизаторов, и имеется возможность определить, от которого из них пришел пакет с данной меткой.
В связи с этим обстоятельством вероятность того, что пространство меток будет исчерпано, очень мала.
Для распределения меток может использоваться либо специальный протокол LDP (Label Distribution Protocol), либо модифицированная версия одного из существующих протоколов сигнализации (например, протокола RSVP).
Каждый LSR содержит таблицу, которая ставит в соответствие паре величин “входной интерфейс, входящая метка” пару величин “выходной интерфейс, исходящая метка”. Получив пакет, LSR определяет для него выходной интерфейс (по входящей метке и по номеру интерфейса, куда пакет поступил). Входящая метка заменяется исходящей (записанной в соответствующем поле таблицы), и пакет пересылается к следующему LSR. Вся операция требует лишь одноразовой идентификации значений в полях одной строки таблицы и занимает гораздо меньше времени, чем сравнение IP-адреса отправителя с адресным префиксом в таблице маршрутов при традиционной маршрутизации.
MPLS предусматривает два способа пересылки пакетов. При одном способе каждый маршрутизатор выбирает следующий участок маршрута самостоятельно, а при другом заранее задается цепочка маршрутизаторов, через которые должен пройти пакет. Второй способ основан на том, что маршрутизаторы на пути следования пакета действуют в соответствии с инструкциями, полученными от одного из LSR данного LSP (обычно - от нижнего, что позволяет совместить процедуру “раздачи” этих инструкций с процедурой распределения меток).
Поскольку принадлежность пакетов тому или иному FEC определяется не только IP-адресом, но и другими параметрами, нетрудно организовать разные LSP для потоков пакетов, предъявляющих разные требования к QoS. Каждый FEC обрабатывается отдельно от остальных - не только в том смысле, что для него образуется свой LSP, но и в смысле доступа к общим ресурсам (полосе пропускания канала, буферному пространству). Поэтому технология MPLS позволяет очень эффективно поддерживать требуемое QoS, соблюдая предоставленные пользователю гарантии.
Конечно, подобный результат удается получить и в обычных IP-сетях, но решение на базе MPLS проще и гораздо лучше масштабируется.
10.8 Обслуживание очередей
Алгоритмы обслуживания очередей позволяют предоставлять разный уровень QoS трафику разных классов. Обычно используется несколько очередей, каждая из которых занимается пакетами с определенным приоритетом. Требуется, чтобы высокоприоритетный трафик обрабатывался с минимальной задержкой, но при этом не занимал всю полосу пропускания, и чтобы трафик каждого из остальных типов обрабатывался в соответствии с его приоритетом.
Обслуживание очередей включает в себя алгоритмы:
• организации очереди;
• обработки очередей.
10.8.1 Алгоритмы организации очереди
Существует два основных алгоритма организации очереди:
Tail Drop и Random Early Detection.
10.8.1.1 Алгоритм Tail Drop
Принцип алгоритма прост - задается максимальный размер очереди (в пакетах или в байтах), вновь прибывающий пакет помещается в конец очереди, а если очередь уже полна - отбрасывается.
Однако при использовании протокола TCP, когда пакеты начинают теряться, модули TCP в рабочих станциях решают, что в сети перегрузка и замедляют передачу пакетов. При заполненной очереди возможны случаи, когда несколько сообщений отбрасываются друг за другом - в результате целый ряд приложений решит замедлить передачу. Затем приложения начнут зондировать сеть, чтобы определить, насколько она загружена, и буквально через несколько секунд возобновят передачу в прежнем темпе, что опять приведет к потерям сообщений.
В некоторых ситуациях данный алгоритм может вызвать так называемый эффект “локаута” (lock-out). Это происходит в тех случаях, когда очередь монополизирует либо один поток пакетов, либо несколько потоков, случайно или по необходимости синхронизированных (например, потоков, несущих изображение и его звуковое сопровождение), что препятствует попаданию в очередь пакетов остальных потоков.
Алгоритм Tail Drop приводит к тому, что очереди оказываются заполненными (или почти заполненными) в течение длительного периода времени. Так происходит, поскольку алгоритм сигнализирует только о том, что очередь полна.
Большой размер очередей сильно увеличивает время доставки пакета от одной рабочей станции к другой. Поэтому желательно, чтобы средний размер очередей в маршрутизаторах был невелик. С другой стороны, известно, что трафик в сети, как правило, неравномерен, и поэтому маршрутизатор должен иметь буфер, размер которого достаточен для того, чтобы “амортизировать” неравномерность трафика.
Имеются альтернативные алгоритмы отбрасывания пакетов: Random Drop (отбрасывание случайно выбранного) и Drop from Front (отбрасывание первого). Принцип работы алгоритма Random Drop понятен из его названия. При заполнении очереди отбрасывается не пакет, пришедший последним, а пакет, выбираемый из очереди случайно. Такой алгоритм предъявляет более высокие требования к вычислительным ресурсам маршрутизатора, поскольку он производит с очередью более сложные операции. Алгоритм Drop from Front отбрасывает пакет, стоящий в очереди первым. Помимо значительного снижения вероятности “локаута”, этот алгоритм выгодно отличается от алгоритма Tail Drop тем, что при использовании протокола TCP рабочая станция раньше узнает о перегрузке в сети и, соответственно, раньше снижает скорость передачи пакетов.
10.8.1.2 Алгоритм Random Early Detection (RED)
Суть алгоритма в том, что когда размер очереди превышает некоторое пороговое значение, прибывающий пакет отбрасывается с вероятностью, зависящей оттого, насколько превышен установленный порог. Обычно предусматривается два пороговых значения. Когда длина очереди переходит за первый порог, вероятность отбрасывания пакета линейно возрастает от 0 (у первого порога) до 1 (у второго порога). Положение второго порога выбирается с таким расчетом, чтобы в оставшемся после него “хвосте” очереди мог поместиться пакет, длина которого несколько превышает среднюю. По мере приближения длины очереди ко второму порогу, растет вероятность того, что прибывший пакет будет отброшен в связи с тем, что он не умещается в очереди (несмотря на наличие “хвоста”), при этом пакеты большего размера имеют больше шансов быть отброшенными, чем пакеты меньшего размера.
При малых размерах очередей метод RED более эффективен, чем другие методы. Он также более устойчив к трафику, имеющему “взрывной” характер.
10.8.2 Алгоритмы обработки очередей
Алгоритмы обработки очередей составляют одну из основ механизмов обеспечения гарантированного качества обслуживания в сетевых элементах.
Разные алгоритмы нацелены на решение разных задач и по-разному воздействует на качество обслуживания сетью трафика разных типов. Тем не менее, возможно и комбинированное применение нескольких алгоритмов.
10.8.2.1 Стратегия FlFO
Алгоритм обслуживания очередей Firstin, FirstOut (FIFO), также называемый First Come First Served является самым простым. Пакеты обслуживаются в порядке поступления без какой-либо специальной обработки.

Такая схема приемлема, если исходящий канал имеет достаточно большую свободную полосу пропускания. Алгоритм FIFO относится к так называемым неравноправным схемам обслуживания очередей, так как при его использовании одни потоки могут доминировать над другими и захватывать несправедливо большую часть полосы пропускания. В связи с этим применяются равноправные схемы обслуживания, предусматривающие выделение каждому потоку отдельного буфера и равномерное разделение полосы пропускания между разными очередями.
10.8.2.2 Очередь с приоритетами
Очередь с приоритетами (Priority Queuing) - это алгоритм, при котором несколько очередей FIFO (могут использоваться алгоритмы Tail Drop, RED и т.д.) образуют одну систему очередей. В случае “ простейшего приоритетного обслуживания трафик определенных классов имеет безусловное преимущество перед графиком других классов. Например, если все IPX-пакеты имеют более высокий приоритет, чем IP-пакеты, то какова бы ни была ценность IP данных, IPX данные будут иметь первоочередной приоритет при разделе доступной полосы. Такой алгоритм гарантирует своевременную доставку лишь наиболее привилегированного трафика.

Рис. 10.6 Очереди с приоритетами
Назначение разным потокам нескольких разных приоритетов производится по ряду признаков, таких как источник и адресат пакета, транспортный протокол, номер порта.
Пакет каждого потока помещается в очередь, имеющую соответствующий приоритет.
Хотя трафик более высокого приоритета получает лучшее обслуживание, чем он мог бы получить при использовании FIFO, некоторые фундаментальные проблемы остаются нерешенными. Например, если используются очереди Tail Drop, то остаются проблемы больших задержек, “локаута” и т.д. Некоторые прикладные программы пытаются использовать весь доступный ресурс. Если им предоставлена наиболее приоритетная очередь, то очереди с низким приоритетом будут блокированы в течение длительного времени, или же низкоприоритетный трафик встретит настолько большую задержку в результате следования по окружному пути, что станет бесполезным. Это может привести к прекращению менее приоритетных сеансов связи или, по крайней мере, сделает их практически непригодными.
10.8.2.3 Class-Based Queuing (CBQ)
При использовании этого механизма трафику определенных классов гарантируется требуемая скорость передачи, а оставшийся ресурс распределяется между остальными классами. Например, администратор может зарезервировать 50% полосы пропускания для SNA-трафика, а другие 50% разделить между остальными протоколами, такими как IP и IPX.
Обработка очередей по алгоритму Class-Based Queuing, CBQ предполагает, что трафик делится на классы. Определение класса трафика в значительной степени произвольно. Класс может представлять весь трафик, проходящий через данный интерфейс, трафик определенных приложений, трафик, направленный к заданному подмножеству получателей, трафик с качеством услуг, гарантированным протоколом RSVP. Каждый класс имеет собственную очередь, и ему гарантируется, по крайней мере, некоторая доля пропускной способности канала. Драйвер интерфейса обходит все очереди по кругу и передает некоторое количество пакетов из каждой очереди. Если какой-либо класс не исчерпывает предоставленный ему лимит пропускной способности, то доля полосы пропускания, выделяемая каждому из остальных классов, пропорционально увеличивается.
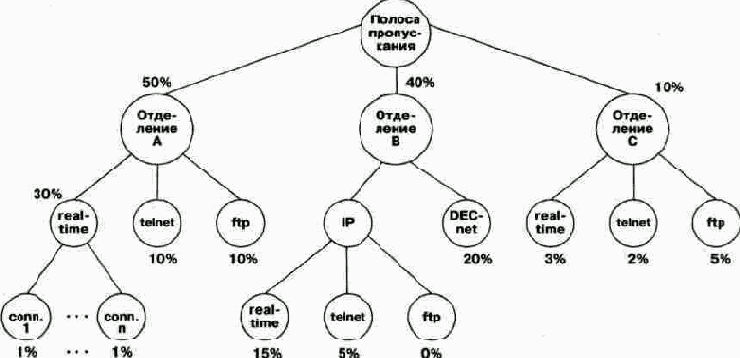
Алгоритм CBQ использует иерархическую организацию классов.
Например, в корпоративной сети иерархия может выглядеть так, как показано на рис. 10.7. При разделении недоиспользованного кем-то ресурса классы, принадлежащие той же ветви дерева, имеют первоочередной приоритет.
Как и в предыдущем случае, используются очереди FIFO, следовательно, для потоков, разделяющих одну очередь, остаются проблемы, присущие FIFO, но гарантируется некоторая справедливость распределения ресурсов в сети между разными очередями. Кроме того, в отличие от приоритетного обслуживания, CBQ не допускает блокировки очереди и дает возможность учитывать использование сети разными классами.
10.8.2.4 Взвешенные очереди
Если необходимо обеспечить для всех потоков постоянное время задержки, и не требуется резервирование полосы пропускания, то можно воспользоваться алгоритмом Weighted Fair Queuing.

Взвешенная справедливая очередь (Weighted Fair Queuing, WFQ) является частным случаем CBQ, когда каждому классу соответствуют свой поток (ТСР-сеанс и т.д.). Как и в случае CBQ, каждому классу WFQ отводится одна очередь FIFO и гарантируется некоторая часть пропускной способности канала, в соответствии с весовым коэффициентом потока. Если некоторые потоки не используют предоставленную им полосу пропускания полностью, то другие потоки соответственно увеличивают свою долю. Так как в данном случае каждый класс - это отдельный поток, то гарантия пропускной способности эквивалентна гарантии максимальной задержки. Зная параметры сообщения, можно по известным формулам вычислить его максимальную задержку при передаче по сети. Выделение дополнительной пропускной способности позволяет уменьшить максимальную задержку.
Алгоритм WFQ гарантирует, что очереди не будут лишены своей доли полосы пропускания, и что трафик получит предсказуемое QoS. Трафик, не использующий целиком свою долю полосы, будет обслуживаться в первую очередь, а оставшаяся полоса будет разделена между остальными потоками.
Определение веса потока производится по полю precedence заголовка IP-пакета. Значение данного поля лежит в пределах от 0 до 7. Чем выше значение, тем большая полоса выделяется потоку.
Очереди в WFQ могут быть связаны с механизмом сглаживания пульсации трафика. Такой механизм используется, в основном, для трафика данных, поскольку он, как правило, очень неравномерен.
10.8.3 Алгоритмы сглаживания пульсации графика
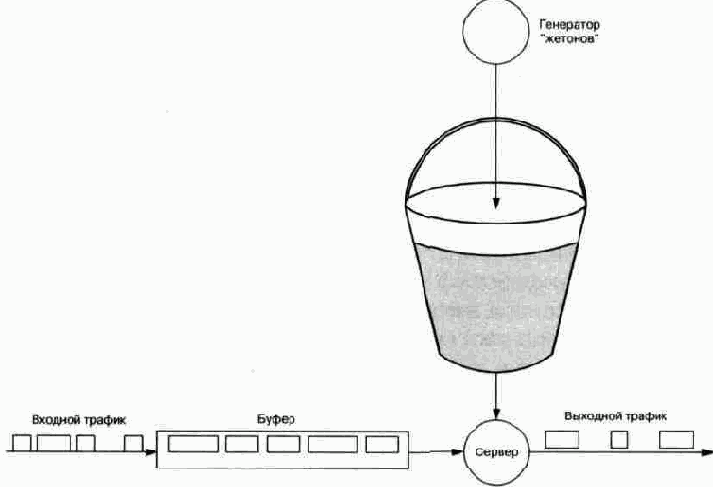
10.8.3.1 Алгоритм Leaky Bucket
Алгоритм “дырявое ведро” обеспечивает контроль и, если нужно, сглаживание пульсации трафика. Алгоритм позволяет проверить соблюдение отправителем своих обязательств в отношении средней скорости передачи данных и пульсации этой скорости.
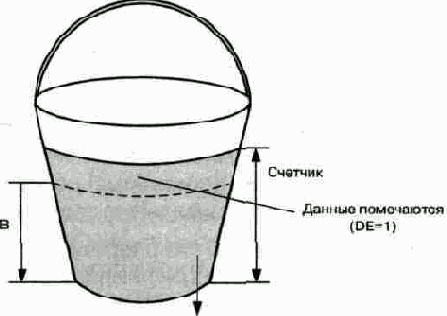
Представим себе ведро, в котором накапливаются данные, получаемые от отправителя. В днище ведра имеются отверстия, через которые данные “вытекают” из него для дальнейшей обработки (или передачи). Через определенные интервалы времени подсчитывается объем данных, которые накопились в ведре в течение интервала, предшествовавшего моменту подсчета. Если объем не превышает порога В, всплеск скорости передачи данных внутри этого интервала считается нормальным, и никаких действий не производится. Если объем накопившихся данных превысил порог В, все пакеты, оказавшиеся выше порога, но ниже краев ведра, снабжаются меткой DE (Discard Eligibility), а те, которые не поместились в ведре, отбрасываются. В следующем интервале данные продолжают поступать в ведро и вытекать из него в обычном порядке (независимо от наличия меток), но если ведро переполняется, то отбрасываются не вновь поступающие пакеты, а пакеты с меткой DE, которые еще не успели вытечь. Если при следующем подсчете окажется, что объем данных в ведре ниже порога В, то никаких действий не производится. Если порог превышен, и в числе пакетов, оказавшихся выше порога, имеются пакеты без метки DE, они получают такую метку.
Одна из версий этого алгоритма, называемая Generic Cell Rate Algorithm (GCRA), применяется в сетях ATM для контроля некоторых параметров.
10.8.3.2 Алгоритм “Token Bucket”
Алгоритм выполняет “калибровку” трафика, т.е. уменьшает до заданного предела пульсацию скорости потока данных и гарантирует, что не будет превышена заданная средняя скорость этого потока.
Имеется некое “ведро”, в которое через равные промежутки времени поодиночке падают одинаковые жетоны; каждый жетон равноценен определенному числу байтов. Имеется буферный накопитель, в котором образуется очередь пакетов, требующих дальнейшей обработки (или передачи). Система работает так, что если количество жетонов в ведре равноценно числу байтов, не меньшему чем содержится в пакете, который стоит в очереди первым, этот пакет выводится из очереди для дальнейшей обработки, и одновременно соответствующее количество жетонов изымается из ведра. Если же жетонов в ведре недостаточно, пакет ожидает, пока их наберется столько, сколько нужно. Таким образом, генератор, определяющий частоту, с которой жетоны падают в ведро, контролирует скорость продвижения пакетов, а буферный накопитель сглаживает ее пульсацию.
Если трафик снизился настолько, что в буферном накопителе не осталось ни одного пакета, подача жетонов в ведро прекращается, когда в нем наберется такое их количество, которое примерно равноценно числу байтов в пакете средней длины. Как только в накопитель снова начнут поступать пакеты, подача жетонов в ведро должна быть возобновлена.